IA para Humanos. Parte 2

La vida secreta de las palabras
¿Qué brujería convierte una sola línea de texto en un resumen del Quijote o una imagen en 4K? ¿Podrías convertir un texto de Lorca en comida para ChatGPT?
En la primera parte de esta serie de posts explicamos, de manera general, como funciona el Machine Learning y las Redes Neuronales Artificiales. Si no te has pasado por allí, ve a echarle un ojo antes de seguir. En estos tiempos convulsos, es posible que utilizando o investigando sobre alguna de las herramientas actuales de Inteligencia Artificial hayas pensado: Sí, sí, esto de las Redes Neuronales está muy bien, pero, si las IAs trabajan con números. ¿Cómo manejan el lenguaje natural? ¿Acaso podemos convertir texto en matemáticas?
Es lógico que pienses que una simple palabra, en principio, no significa nada para un algoritmo que utiliza internamente álgebra. Y tienes razón. Al igual que no le echarías Monster a un coche de gasolina (excepto si lo conduce Verstappen) o usarías Cruzcampo para regar calabacines (pobres calabacines); no puedes añadir texto de entrada en bruto a un algoritmo de Inteligencia Artificial. Pero, que pasa si te dijera que podemos hacer un poco de magia y convertir el idioma de las humanidades en el lenguaje de la ciencia.
Imagina esta situación. Estamos en una gran entrevista de trabajo. La más grande que hayas visto jamás, con miles de candidatos y candidatas. Existen vacantes para diferentes puestos dentro de una compañía y se debe detectar quienes son los más aptos para dichas vacantes. En principio todos los candidatos parecen iguales. A priori, no se conoce ninguna característica especial de los aspirantes. Por tanto, se someten a diferentes pruebas y entrevistas, todas ellas conjuntas. De estas entrevistas, los reclutadores empiezan a ver ciertos patrones entre los candidatos. Cómo se relacionan entre ellos, qué características los hace singulares, quienes son más similares y más diferentes. Tras un duro día de trabajo, los reclutadores han modelizado individualmente a cada candidato. Saben perfectamente cuál debe ser su rol y donde pueden encajar dentro de la compañía. Saben cuáles trabajarán mejor en equipo y cuáles no, cuáles tienen mayores capacidades de liderazgo, etc. En resumen, han convertido sujetos random, en individuos con características y particularidades únicas. Lo que ha ocurrido aquí es que los aspirantes random se han convertido en Embeddings. Apunta esta palabra porque a partir de ahora será muy importante en tu vida.
Hasta aquí, todo homologado y perfecto. Pero te estarás preguntando, ¿Qué son en realidad los Embeddings? Vamos a hacer un poquito de mates, pero no muchas, no te preocupes. Para ello, vamos a retrotraernos a 4º de la ESO y recordar a nuestros amigos los vectores. Para explicarlo de manera sencilla, en matemáticas, un vector es un conjunto de números que representan diferentes magnitudes o características. Por ejemplo, si queremos representar el movimiento de un vehículo podemos representarlo como un vector de 3 elementos con esta la pinta: [120, 12, 10]. El primer dígito (120) representa la distancia recorrida, el segundo (12) el tiempo en movimiento y el tercero (10) la velocidad. Bien, de esta forma se pueden representar multitud de características de una entidad. ¿Recuerdas el tiempo y temperatura del horno que vimos en la parte uno? ¿A qué los datos de cada ejemplo tenían pinta de vector?
Entonces, se nos enciende la bombilla y nos preguntamos, ¿Las palabras también poseen características particulares, al igual que las poseían los candidatos de las entrevistas? ¿Pueden las palabras representarse como estos vectores? Pues, te adelanto que la respuesta es sí. Las palabras, por el contexto en el que son utilizadas, pueden contener multitud de características. Pongamos un ejemplo, la palabra rey. La palabra rey posee diferentes características intrínsecas. Algunas de ellas podrían ser: sustantivo, género masculino, número singular, estatus social elevado o alta corruptibilidad.
Perfecto, ahora ¿cómo relacionamos los vectores que son un elemento puramente matemático con las palabras? ¿Qué representará cada uno de los elementos del vector? Pongamos que tenemos un texto cualquiera en idioma castellano. A cada la palabra del texto la sustituimos por un vector aleatorio. Por ejemplo, a la palabra rey la sustituimos por [1, 5, 3, 7]. En principio, estos números no representan nada. Cabe destacar que, para el ejemplo, hemos usado un vector pequeñito. Normalmente, los vectores suelen ser de dimensiones mayores.
Ya tenemos las palabras con representación matemática. ¿Cuál será el siguiente paso? Quizá podamos aplicar alguna herramienta que encuentre patrones y relaciones entre las distintas palabras y, además, modifique el valor de los vectores acorde a esas relaciones. ¡Eso es! Debemos aplicar un algoritmo para generar los Embeddings. ¡Incluso se pueden utilizar Redes Neuronales para este propósito! Te diré que, para crear Embeddings, uno de los métodos más extendidos a día de hoy es BERT. BERT utiliza una Red Neuronal Bidireccional basada en Transformers. ¿Transformers? ¿El santo Grial de la IA moderna? Sí, pero ¡chsss! Eso ya lo trataremos más adelante. También, existen otros métodos más simples basados en el análisis de la co-ocurrencia de palabras en un texto, como por ejemplo GloVe. Sin embargo, no te quiero abrumar con las diferentes técnicas para generar Embeddings. Si te pica la curiosidad, aunque esto ya es café para los muy cafeteros, puedes buscar información acerca de estas técnicas en Google, ¡o en Bing!
Lo que debes tener claro es que, de forma similar a como los reclutadores descubrían las características genuinas de cada candidato, estos algoritmos son capaces de explorar patrones y relaciones entre las palabras, o más bien debería decir entre los vectores que representan palabras. De forma que, tras ejecutar los algoritmos, el valor interno de los elementos de los vectores se ha modificado con el objetivo de aplicar estas relaciones y características. ¡Hemos creado Embeddings!
Y ¡wuolah! El texto pasa de tener un sentido puramente lingüístico a poseer naturaleza numérica. Lo que antes eran palabras, que una Inteligencia Artificial era incapaz de relacionar, ahora posee un orden, lenguaje y sentido matemático que ha establecido fuertes relaciones internas. Características como género, número, edad, que antes estaban representadas gramaticalmente, ahora también los están algebraicamente en estos vectores. De hecho, podemos conocer la similitud entre todas las palabras de un diccionario. Si representásemos diferentes palabras en un gráfico de 2 dimensiones, podríamos visualizar la distancia matemáticas entre ellas tal como se muestra en la imagen inferior.
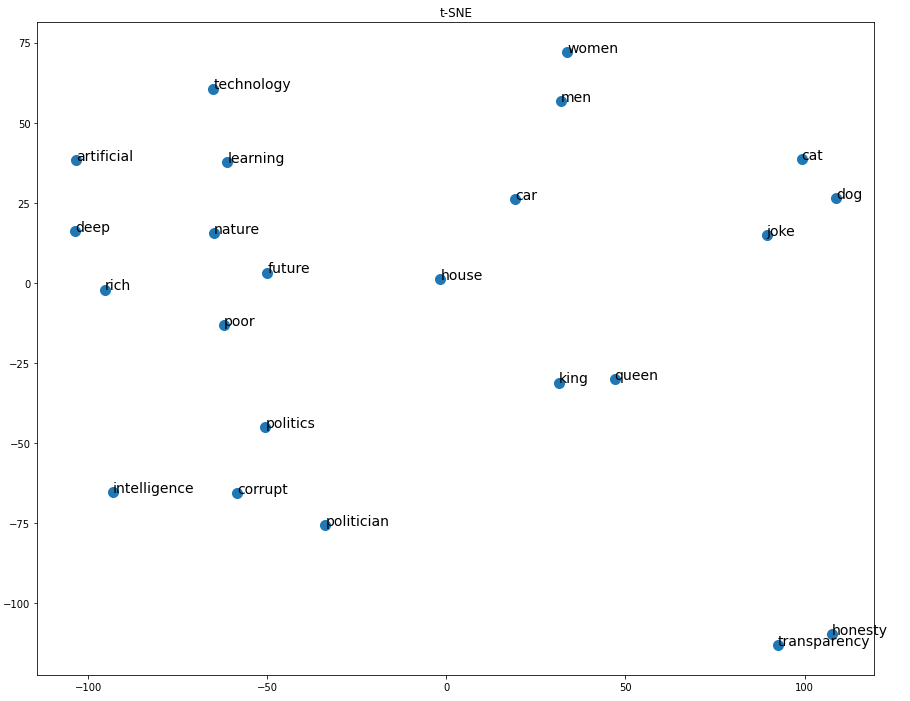
También, podemos explorar esta nueva naturaleza adquirida de forma empírica. Podemos chequear la relación entre estos vectores que representan palabras. Un procedimiento típico utilizado para saber lo semejantes que son dos vectores, es evaluar la similitud del coseno. Si son muy semejantes, la similitud del coseno entre ambos vectores será próxima a 1. Si son opuestos será próxima a -1. Imaginemos que la palabra político está representada por un vector cualquiera y la palabra honradez por otro. Al ejecutar la función de similitud del coseno veremos que da un resultado próximo a 0.18. Mientras que, si comparamos las palabras político y corrupción, el resultado será cercano a 0.5. Las palabras hablan por sí solas, no me invento nada, el resultado es una simulación real. Si buscáis bien, en internet existen herramientas donde podéis probar estos resultados.
Y claro, en este momento es donde salen a jugar los mayores. Los Embeddings pueden utilizarse para multitud de aplicaciones increíbles dentro del Deep Learning. Por ejemplo, si entrenamos una Red Neuronal con estos Embeddings, podemos intentar adivinar cuál es la siguiente palabra en una oración. El modelo de Red Neuronal, en función de las características de las palabras del texto, realizará una predicción sobre cuál es el término más probable para rellenar el hueco. También, podemos entrenar un modelo para distinguir si una publicación tiene una connotación positiva o negativa, aplicar estilos específicos a una obra y con un par de vueltas más, GENERAR TEXTO. Pero esto, lo dejamos para el próximo post, que es donde vendrá el mandangón.
Escribiendo desde un sótano en la Deep Web, atentamente math.